
Today I'd like to talk about Bayes' Theorem, especially since it's come up in the comments section several times. It's named after St. Thomas Bayes (rhymes with "phase"). It can be used as a general framework for evaluating the probability of some hypothesis about the world, given some evidence, and your background assumptions about the world.
Let me illustrate it with a specific and very non-original example. The police find the body of someone who was murdered! They find DNA evidence on the murder weapon. So they analyze the DNA and compare it to their list of suspects. They have a huge computer database containing 100,000 people who have previously had run-ins with the law. They find a match! Let's say that the DNA test only gives a false positive one out of every million (1,000,000) times.
So the prosecutor hauls the suspect into court. He stands up in front of the jury. "There's only a one in a million chance that the test is wrong!" he thunders, "so he's guilty beyond a reasonable doubt; you must convict."
The problem here—colloquially known as the prosecutor's fallacy—is a misuse of the concept of conditional probability, that is, the probability that something is true given something else. We write the conditional probability as 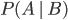 , the probability that
, the probability that 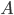 is true if it turns out that
is true if it turns out that 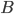 is true. It turns out that is not the same thing in general as
is true. It turns out that is not the same thing in general as 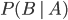 .
.
When we say that the rate of false positives is 1 in a million, we mean that
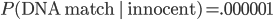
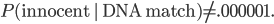
Suppose that there's a .5 chance that the guilty person is on the list, and a .5 chance that he isn't. Then prior to doing the DNA test, the probability of a person on the list being guilty is only 1 : 200,000. The positive DNA test makes that person's guilt a million times more likely, but this only increases the odds to 1,000,000 : 200,000 or 5 : 1. So the suspect is only guilty with 5/6 probability. That's not beyond a reasonable doubt. (And that's before considering the possibility of identical twins and other close relatives...)
Things would have been quite different if the police had any other specific evidence that the suspect is guilty. For example, suppose that the suspect was seen near the scene of the crime 45 minutes before it was committed. Or suppose that the suspect was the murder victim's boyfriend. Suppose that the prior odds of such a person doing the murder rises to 1 : 100. That's weak circumstantial evidence. But in conjunction with the DNA test, the ratio becomes 1,000,000 : 100, which corresponds to a .9999 probability of guilt. Intuitively, we think that the circumstantial evidence is weak because it could easily be compatible with innocence. But if it has the effect of putting the person into a much smaller pool of potential suspects, then in fact it raises the probability of guilt by many orders of magnitude. Then the DNA evidence clinches the case.
So you have to be careful when using conditional probabilities. Fortunately, there's a general rule for how to do it. It's called Bayes' Theorem, and I've already used it implicitly in the example above. It's a basic result of probability theory which goes like this:
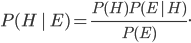
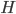 given some evidence
given some evidence 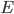 which we just observed, we start by asking what was the prior probability
which we just observed, we start by asking what was the prior probability 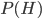 of the hypothesis before taking data. Then we ask what is the likelihood
of the hypothesis before taking data. Then we ask what is the likelihood 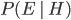 , if the hypothesis were true, we'd see the evidence that we did. We multiply these two numbers together.
, if the hypothesis were true, we'd see the evidence that we did. We multiply these two numbers together.
Finally, we divide by the probability 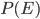 of observing that evidence . This just ensures that the probabilities all add up to 1. The rule may seem a little simpler if you think in terms of proability ratios for a complete set of mutually exclusive rival hypotheses
of observing that evidence . This just ensures that the probabilities all add up to 1. The rule may seem a little simpler if you think in terms of proability ratios for a complete set of mutually exclusive rival hypotheses 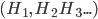 for explaining the same evidence . The prior probabilities
for explaining the same evidence . The prior probabilities 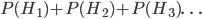 all add up to 1. is a number between 0 and 1 which lowers the probability of hypotheses depending on how likely they were to predict . If
all add up to 1. is a number between 0 and 1 which lowers the probability of hypotheses depending on how likely they were to predict . If 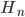 says that is certain, the probability remains the same; if says that is impossible, it lowers the probability of to 0; otherwise it is somewhere inbetween. The resulting probabilities add up to less than 1. is just the number you have to divide by to make everything add up to 1 again.
says that is certain, the probability remains the same; if says that is impossible, it lowers the probability of to 0; otherwise it is somewhere inbetween. The resulting probabilities add up to less than 1. is just the number you have to divide by to make everything add up to 1 again.
If you're comparing two rival hypotheses, doesn't matter for calculating their relative odds, since it's the same for both of them. It's easiest to just compare the probability ratios of the rival hypotheses, because then you don't have to figure out what is. You can always figure it out at the end by requiring everything to add up to 1.
For example, let's say that you have a coin, and you know it's either fair (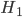 ), or a double-header
), or a double-header 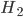 . Double-headed coins are a lot rarer than regular coins, so maybe you'll start out thinking that the odds are 1000 : 1 that it's fair (i.e.
. Double-headed coins are a lot rarer than regular coins, so maybe you'll start out thinking that the odds are 1000 : 1 that it's fair (i.e. 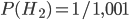 ). You flip it and get heads. This is twice as likely if it's a double-header, so the odds ratio drops down to 500 : 1 (i.e.
). You flip it and get heads. This is twice as likely if it's a double-header, so the odds ratio drops down to 500 : 1 (i.e. 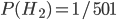 ). A second heads will make it 250 : 1, and a third will make it 125 : 1 (i.e.
). A second heads will make it 250 : 1, and a third will make it 125 : 1 (i.e. 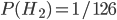 ). But then you flip a tails and it becomes 1 : 0.
). But then you flip a tails and it becomes 1 : 0.
If that's still too complicated, here's an even easier way to think about Bayes' Theorem. Suppose we imagine making a list of every way that the universe could possibly be. (Obviously we could never really do this, but at least in some cases we can list every possibility we actually care about, for some particular purpose.) Each of us has a prior, which tells us how unlikely each possibility is (essentially, this is a measure of how surprised you'd be if that possibility turned out to be true). Now we learn the results of some measurement . Since a complete description of the universe should include what is, the likelihood of measuring has to be either 0 or 1. Now we simply eliminate all of the possibilities that we've ruled out, and rescale the probabilities of all the other possibilities so that the odds add to 1. That's equivalent to Bayes' Theorem.
I would have liked to discuss the philosophical aspects of the Bayesian attitude towards probability theory, but this post is already too long without it! Some other time, maybe. In the meantime, try this old discussion here.
Gilbert wrote:
To stave off a possible misunderstanding, I'm a Christian. By calling Bayesianism a "root error" I don't mean it's at the root of your thus escapable faith, I mean the conversation that grows from it is basically moot.
On to statistical ideology:
In a system where credence is always a real number, and all propositions and conditional propositions have credences attached to them, and there is a stream of confirmations and disconfirmations of propositions, so that the credences need to be updated, I actually agree that that updating needs to happen according to The Rev. T. Bayes's theorem. (Or something equivalent, if we're talking odds ratios or logarithms or whatever, then the formal rule will be different, but there will always be some isomorphism to the canonical one.) Basically I'm aware of Cox's theorem and where its preconditions hold I'll except its consequence.
But I think that's a rather big set of assumptions if you want to talk about all beliefs. Basically, when people talk about probabilities I want to know what model they are talking about. On what \sigma-algebra does the probability measure live, what structures does that presuppose in reality, how do those numbers relate to experience, etc. Frequencies of repeatable events are the paradigmatic way of answering that question, but I'd agree that some other ways are possible.
For example, consistent betting odds on all relevant events are one way to do it. But look at the baggage that introduces: First, it assumes a structure of possible events. For example, if you bet on who will win an election, there will be a (probably implicit) understanding that the bet is off if there is a revolution and the election gets canceled, because that just doesn't count as an 'event' in the probability space you're considering. Likewise, any bet for money is moot if money gets abolished in some kind of communist revolution. Second, it assumes that bets will be decisively settled by future information. That makes it basically impossible to bet on controversial past events, where new information is unlikely to be forthcoming. Third, it assumes that people have beliefs on all relevant events and are willing to bet on them for profits of \epsilon. But real people are ignorant and risk-averse and rightly weary of asymmetrical information. Now often this is close enough for practical purposes, which is why insurances and bookmakers can stay in business. But it is still a model and the probability-talk is only meaningful in that model.
And I can make similarly restricted models of rationality that don't involve beliefs being real numbers. For example, one could imagine binary beliefs with ordinal certainties. In that model beliefs would change iff they turn out incompatible with beliefs of higher precedence. The path-dependance could be removed by alway evaluating all evidence against the original belief set. Intuitive (im-)plausibility would be encoded in the preference order. And yet the model doesn't include any real numbers. There is no question of how certain one is of a given belief, only of which of two beliefs one is more certain. Of course this is a cartoon of the actual thinking process, but then so is Bayesianism.
As for what we actually do, I think the process is basically evidence and rational minimum standards constraining possible beliefs and gut feelings within that constraints. And I think most of the debate on this post could be translated to that process without loss of persuasiveness. Some probabilities get canceled out without being named and others are given as large ranges. Nobody ends up with an actual numerical probability for Christianity. And the question whether two factors cancel out could easily be replaced with the question whether some scenarios are plausible. To me that looks a bit like the Drake equation, where a wild guess suddenly sounds a lot more sciency, but looking closer it's just replaced with six wild guesses. Of course you have a good argument rather than a wild guess of a number, but I think the problem of the indeterminate formalization not really adding anything is the same.
My reply:
To me Bayesianism is a model of how an idealized rational agent ought to process evidence, not a model of anything specific happening in the external objective "real world", nor a model of how people actually do behave psychologically--and that's precisely why it can be applied to every situation. Of course we do not live up to the ideal. I don't claim that we've thought of every possible way for the world to be (although I think the assumption that there is a set of all possibile ways for the world to be is extremely reasonable, modulo some concerns involving huge infinities in set theory). If it turns out we've left out a possibility, and we think of it later, we can always go back and do the analysis again. Or, if we're worried about leaving other possibilities out but can't think of any, then we can assign some probability to "something else" based on our--yes, gut feeling--about how likely it is we're missing an important alternative possibility in that subject matter.
Nor does it bother me that most of us are uncomfortable assinging precise prior probability values to every situation. That's just because we aren't idealized rational agents. In situations where you have to pick a particular number, you just judge it by eye and pick what seems to be about the right place, just as if you were deciding how high a picture should go on a wall in order to look the best. The true power of Bayesianism comes, not in the gut-level assignments of probability which as you say mostly go by guessing, but when people start disputing whether a particular kind of argument really provides evidence or not. Bayesianism as a sort of "Court of Appeals" for resolving such questions works fantastically well.
Regarding the Dutch book argument, I think you're focussing too much on the trappings of the argument, and not enough on the underlying principles at stake. Of course, money isn't always available (although even after the communist revolution you'd expect to care about some things that could be approximated by real utility values), nor is an impartial bookie who doesn't exploit any asymmetrical knowledge, nor is there an oracle who call tell us who won bets on any subject. But that doesn't matter! As long as there's a correct answer to the question of what you would do hypothetically if these things did exist, you have a set of probability assignments right there. And I have a strong intuition that whether or not I am rational to believe a proposition X can't possibly depend on whether the money etc. actually exists. It doesn't make any sense to say that Bayesianism is true in Los Vegas but false elsewhere.
Furthermore, I've never seen any other model of probability which has a similar scope to Bayesianism but doesn't get things horribly wrong somewhere. For example, your ordinal model is clearly ridiculous since it implies that even a million contradictions with "2" beliefs would never be sufficient to overcome a "3" belief, despite the fact that you're clearly not totally sure of a "3" since it could in principle be taken down by a "4". That's silly, and it certainly won't work in Los Vegas. Or for the "prosecutor fallacy" case.
There is a typo in the Bayes formula. On the right side of the equation, the denominator should be P(E).
[Fixed it. Thanks very much, Johannes--AW]
Sometimes people want to see where the subject is going before they invest the time in understanding the math. I have put together a fun series of videos on YouTube entitled “Bayes’ Theorem for Everyone”. They are non-mathematical and easy to understand. And I explain why Bayes’ Theorem is important in almost every field. Bayes’ sets the limit for how much we can learn from observations, and how confident we should be about our opinions. And it points out the quickest way to the answers, identifying irrationality and sloppy thinking along the way. All this with a mathematical precision and foundation. Please check out the first one:
http://www.youtube.com/watch?v=XR1zovKxilw
Hey,
So I am trying to solve a Bayesian problem. It's an off shoot of the 3 prisoner's problem but instead of equal probabilities of 1/3,1/3 and 1/3, the probabilities are 0.15,0.05 and 80%. How do I work this out? Any help will be appreciated